선형 자료 구조는 데이터가 일렬로 차곡차곡 나열된 형태의 자료 구조를 말합니다.
데이터가 한 줄로 정렬되어 있어서 앞에서부터 뒤까지 순서대로 접근하는 특징을 가집니다.
🔗 연결 리스트
연결 리스트는 데이터를 감싼 노드들을 포인터로 연결해 놓은 구조라서, 메모리를 필요할 때마다 가져와서 붙일 수 있습니다. 그래서 공간 활용이 좋고, 중간에 삽입·삭제가 빠릅니다(O(1)). 하지만 임의 위치 탐색은 처음부터 차례대로 따라가야 해서 O(n) 이 걸립니다.
prev 포인터와 next 포인터로 앞과 뒤의 노드를 연결시킨 것이 연결 리스트이며, 연결 리스트는 싱글 연결 리스트로, 이중 연결 리스트, 원형 이중 연결 리스트가 있습니다. 참고로 맨 앞에 있는 노드를 헤드(head)라고 합니다.
- 싱글 연결 리스트 : next 포인터만 가집니다.
- 이중 연결 리스트 : next + prev 두 포인터를 가집니다.
- 원형 이중 연결 리스트 : 마지막 노드의 next가 head를 가리키는 구조입니다.
이중 연결 리스트는 push_front(), push_back(), insert() 등 다양한 위치 삽입이 가능합니다.
#include <bits/stdc++.h>
using namespace std;
int main(){
list<int> a;
for(int i=0;i<10;i++)a.push_back(i);
for(int i=0;i<10;i++)a.push_front(i);
auto it=a.begin();it++;
a.insert(it,1000);
for(auto it:a) couut<<it<<" ";
cout<<'\n;;
a.pop_front();
a.pop_back();
for(auto it:a) cout<<it<<" ";
cout<<'\n';
return 0;
}
/*
9 1000 8 7 6 5 4 3 2 1 0 0 1 2 3 4 5 6 7 8 9
1000 8 7 6 5 4 3 2 1 0 1 2 3 4 5 6 7 8
*/📏 배열(array)
배열은 같은 타입의 데이터가 연속된 메모리 공간에 저장되는 구조입니다. 그래서 인덱스로 바로 접근할 수 있어 O(1) 이며, 랜덤 접근이 가능합니다. 하지만 새로운 데이터를 중간에 넣으려면 한 칸씩 밀어야 해서 삽입·삭제는 O(n) 입니다. 여기서 설명하는 배열은 '정적 배열'을 기반으로 설명합니다.
📉 랜덤 접근과 순차적 접근
직접 접근이라고 하는 랜덤 접근은 동일한 시간에 배열과 같은 순차적인 데이터가 있을 때 임의의 인덱스에 해당하는 데이터에 접근할 수 있는 기능입니다. 이는 데이터를 저장된 순서대로 검색해야 하는 순차적 접근과는 반대입니다.
📉 배열과 연결 리스트 비교
배열은 상자를 순서대로 나열한 데이터 구조이며 몇 번째 상자인지만 알면 해당 상자의 요소를 끄집어낼 수 있습니다. 연결 리스트는 상자를 선으로 연결한 형태의 데이터 구조이며, 상자 안의 요소를 알기 위해서는 하나씩 상자 내부를 확인해봐야 한다는 점이 다릅니다. n번째 요소의 접근(참조)은 배열은 빠르고 연결 리스트는 느립니다. 배열의 경우 그저 상자 위에 있는 요소를 접근하면 되기 때문에 O(1)의 시간 복잡도를 가지고, 연결 리스트는 매번 상자를 열어야 하고 주어진 선을 기반으로 순차적으로 열어야 하기 때문에 접근(참조)의 경우 O(n)의 시간 복잡도를 가집니다. 즉, 참조가 많이 일어나는 작업의 경우 배열이 빠르고 연결리스트는 느립니다. 하지만 데이터 추가 및 삭제는 연결 리스트가 더 빠르고 배열은 으립니다. 배열은 모든 상자를 앞으로 옮겨야 추가가 가능하지만, 연결 리스트는 선을 바꿔서 연결해주기만 하면 되기 때문입니다.
#include <bits/stdc++.h>
using namespace std;
int a[10];
int main(){
for(int i=0;i<10;i++)a[i]=i;
for(auto it:a) cout<<it<<" ";
cout<<'\n';
return 0;
}
/*
0 1 2 3 4 5 6 7 8 9
*/
📦 벡터(vector)
벡터는 크기가 자동으로 늘어나는 동적 배열입니다. 랜덤 접근이 가능하고, 맨 뒤에 push_back(), pop_back()은 거의 O(1)입니다.
왜냐하면 벡터는 필요할 때만 2배로 늘려서 메모리를 재할당하기 때문입니다.
이렇게 가끔 큰 비용이 들지만 평균하면 거의 상수 시간처럼 동작하는 것을 amortized O(1) 이라고 합니다. push_back()을 한다고 해서 매번 크기가 증가하는 것이 아니라 2의 제곱승 + 1마다 크기를 2배로 늘리는 것을 알 수 있습니다. ci를 i번째 push_back()을 할 때 드는 비용(cost)이라고 한다면, ci는 1 또는 1+2ᵏ라는 것을 알 수 있습니다. 그렇다면 n을 push_back()을 한다고 했을 때 드는 비용 T(n)은 다음과 같은 식이라는 것을 알 수 있습니다.
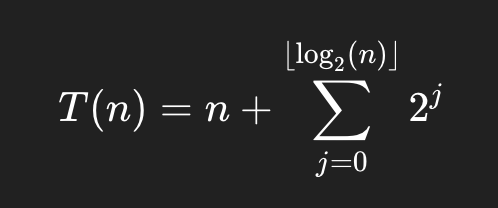
이를 n으로 나누게 되면 push_back()을 할 때 평균적으로 드는 비용을 알 수 있는데, 이것이 바로 3이기 때문에 이는 1이라는 상수 시간보다는 크지만 상수 시간에 가까운 amortized 복잡도를 가진다는 것을 알 수 있습니다. 그렇기 때문에 push_back()은 O(1)의 시간 복잡도를 가진다고 할 수 있습니다.
#include <bits/stdc++.h>
using namespace std;
vector<int> v;
int main(){
for(int i=1;i<=10;i++)v.push_back(i);
for(int a: v)cout<<a<<" ";
cout<<"\n";
v.pop_back();
for(int a:v) cout<<a<<" ";
cout<<"\n";
v.erase(v.begin(),v.begin()+1);
for(int a:v) cout<<a<<" ";
cout<<"\n";
autu a=find(v.begin(),v.end(),100);
if(a==v.end()) cout<<"not found"<<"\n";
fill(v.begin(),v.end(),10);
for(int a:v) cout<<a<<" ";
cout<<"\n";
v.clear();
for(int a:v) cout<<a<<" ";
couut<<"\n";
return 0;
}
/*
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9
2 3 4 5 6 7 8 9
not found
10 10 10 10 10 10 10 10
*/뒤부터 요소를 더하는 push_back(), 맨 뒤부터 지우는 pop_back(), 지우는 erase(), 요소를 찾는 find(), 배열을 초기화하는 clear() 함수가 있습니다.
for(int a:v) cout<<a<<'\n';
for(int i=0;i<v.size();i++) couut<<v[i]<<'\n';
//위의 두 코드는 같은 뜻위의 코드는 "벡터의 요소를 순차적으로 탐색한다."라는 뜻이며, 전자와 후자 코드는 같습니다.
예를 들어 벡터 v에 pair라는 값이 들어간다면 for(pair<int,int>a:v) 방식으로 순회해야 합니다.
🧱 스택(stack)
스택은 마지막에 들어온 데이터가 먼저 나오는 구조(LIFO) 입니다.
- 삽입(push) O(1)
- 삭제(pop) O(1)
- 탐색 O(n)
웹 브라우저 뒤로가기, 재귀 구현 등에 쓰입니다.
#include <bits/stdc++.h>
using namespace std;
stack<int> stk;
int main(){
ios_base::sync_with_studio(false);
cin.tie(NULL)l
for(int i=0;i<10;i++)stk.push(i);
while(stk.size()){
couut<<std.top()<<" ";
stk.pop();
}
}
/*
9 8 7 6 5 4 3 2 1
*/
🚉 큐(queue)
큐는 먼저 들어온 데이터가 먼저 나오는 구조(FIFO) 입니다. CPU 작업 대기열, BFS, 네트워크 요청 처리 등에 씁니다.
- 삽입(push) O(1)
- 삭제(pop) O(1)
- 탐색 O(n)
#include <bits/stdc++.h>
using namespace std;
int main(){
queue<int>q;
q.push(1);
cout<<q.front()<<"\n";
q.pop();
cout<<q.size()<<"\n";
return 0;
}
/*
1
9
*/참고로 C++에서 enqueue()는 push(), dequeue()는 pop()으로 구현되었습니다.
1. 연결리스트와 배열을 설명하고, 차이점을 말해주세요.
배열은 동일한 타입의 데이터를 연속된 메모리 공간에 저장하는 자료구조로, 인덱스를 통해 O(1)로 빠르게 접근할 수 있습니다. 반면 연결 리스트는 각 데이터가 노드로 구성되어 있으며, 노드가 다음 노드를 가리키는 포인터로 연결된 구조입니다. 배열은 중간 삽입이나 삭제 시 데이터 이동이 필요해 비효율적이지만, 연결 리스트는 포인터만 변경하면 되어 삽입과 삭제가 효율적입니다. 대신 배열은 접근 속도가 빠르고, 연결 리스트는 임의 접근이 불가능해 순차 탐색이 필요하다는 차이점이 있습니다.
'Computer Science > Data Structure' 카테고리의 다른 글
| 🔀비선형 자료 구조 (0) | 2025.12.09 |
|---|---|
| ⏳복잡도 (0) | 2025.12.09 |